

MAD, China, and the Semiconductor Showdown (Part 2)


(generated by Midjourney)
In Part 1 of this two-part blog post, I highlighted the macro funding trends as the “AI Wars” between the US and China reach new levels of intensity. In Part 2 of this series, I explore why owning the entire semiconductor stack is crucial to maintaining the (seemingly) accelerating pace of innovations in AI, and how, until recently, investment in onshore semiconductor production hasn’t been given as much focus given the steep curve required to catch up to the production economics in Asia. I contend that the western world’s uncertain access to an unimpeded supply of semiconductors against the backdrop of broader geopolitical tensions in the Taiwan Strait creates a dangerous reflexive loop, with downstream ramifications in the broader commercialization of AI (which I deeply care about as an early-stage investor in the space). On the commercial side, losing access to semiconductors would mean a material slowdown in AI innovation. More broadly (in a geopolitical lens), this may force the major powers to take sub-optimal actions to protect their technological interests. This post is a bit more technical but was something I really enjoyed researching/thinking about. Let’s dive in.
At a high level, the way I think about AI as it makes its way to end-users is that it’s a chain of dependencies all the way down to the physical layer. Typically, the lowest part of the stack that a software company needs to worry about is at the cloud hyperscale layer, where, given enough money and systems expertise, one could theoretically spin up unlimited compute resources (say Nvidia A100s for AI training workloads). This promise of unlimited compute is not really true these days as the cloud hyperscalers reach their compute capacity, as I will mention later in the article. We’ve largely not had to worry about our fundamental ability to access actual hardware – our “World of Atoms”.

In fact, up until recently, the technology community hasn’t really needed to care about companies like TSMC and ASML, because all of that “gunky” physical hardware has been well abstracted away by the time someone writes “import torch”.
Why does the “World of Atoms” matter?
Taking a step back for a brief history lesson, it’s important to understand a) why semiconductor fabrication was originally offshored, and b) why, these days, having semiconductor fabrication capabilities is quickly becoming more important than being able to pull model weights from Hugging Face.
In the decades past, chip fabrication was seen as a commodity to be outsourced, and the arrival of pure-play fabs like TSMC enabled chip design companies to decouple design of hardware and the manufacturing of that hardware. As production processes became more advanced, however, the CapEx required for each successful generation of chips (node shrinks) became significantly more expensive (a leading edge fab might cost 10+ billion).
As an aside, Moore’s Law states that every 18 months, the number of transistors in a chip roughly doubles (although that’s definitely slowed down) —this is one key enabler, in addition to the advances in networking infrastructure, for all of the compute performance we get for free to train ever larger models (and our highly inefficient React Native code in the software engineering world!)
Why capital alone cannot solve our chip production problems
While the US continues to innovate in the world of bits, it has somewhat neglected innovating in the world of atoms (as it pertains to semiconductor manufacturing). To understand why it’s so hard to replicate an end-to-end semiconductor supply chain, here are just a subset of (very) expensive and technologically difficult steps to build an AI accelerator (which ends up looking like a very complex dance between various ecosystem partners).
Hardware design companies (like Nvidia) create chip designs using software from companies like Cadence and Synopsys
These designs are shipped off to facilities owned by TSMC (Taiwan) or Samsung (Korea)
TSMC, in turn operates very expensive EUV (Extreme Ultraviolet) lithography machines made by Netherland company ASML, each of which costs $200M
The lens technology used in these ASML machines comes from German company Zeiss
All of these processes listed above require significant institutional knowledge, requiring long lead times to train such specialized workforces
I’m skipping several steps in the flow of semiconductor manufacturing (some other considerations include advanced packaging and testing), but the essence is that the fabrication of leading-edge chips truly takes a village of an ecosystem of deeply technical companies, relying on the advances and expertise of decades and probably millions of engineering-hours. Additionally, having semiconductor manufacturing isn’t enough, you need actual customers to amortize the enormous initial CapEx. As a result, one of the effects of the exponential cost curve was high industry consolidation as we’ve moved to more advanced manufacturing nodes (see chart below).
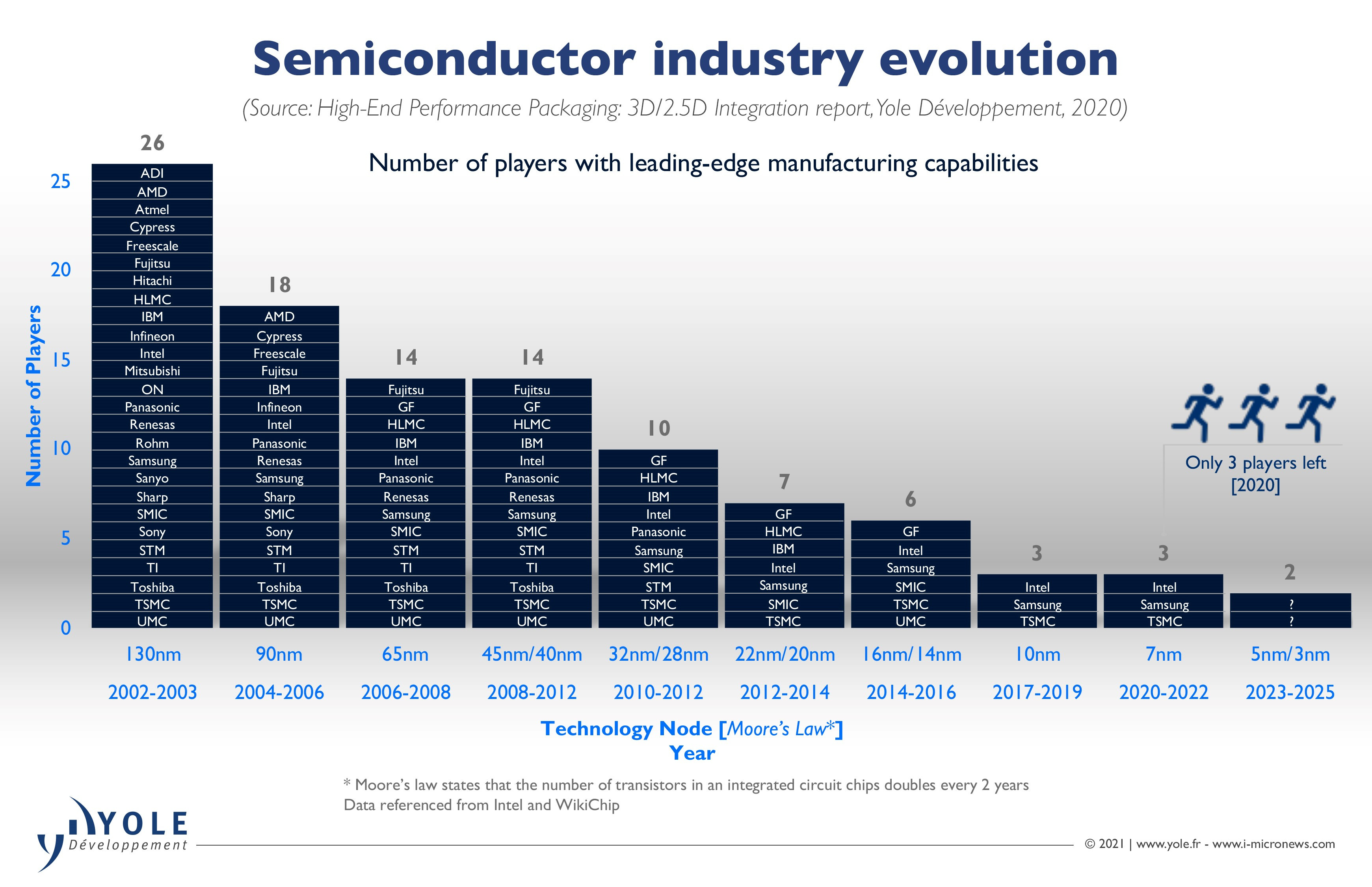
In the US, Intel stands alone as the only domestic company attempting the leading edge (though they are behind Samsung and TSMC). Global Foundries, one of the other leading edge players until relatively recently, essentially gave up at 7nm and have since then disbanded its advanced node exploration teams.
Compute requirements for AI models have outpaced Moore’s Law
Going back to our world of ML/AI, and why we care–the deluge of AI announcements and product launches (GPT-4, Anthropic Claude) is possible from an engineering perspective because of the advances in semiconductor design and fabrication advancements over multiple decades. By this point, we’ve gotten used to the magic/witchcraft of products like GPT-4 and its contemporaries because they exhibit various emergent behaviors (e.g. chain-of-thought prompting). These behaviors are largely the result of scaling the size/training data/training epochs of large language models (LLMs).
The actual training of these multi-hundred billion parameter models (which are considered “embarrassingly parallel”), however, require ever larger fleets of cutting edge ML accelerators designed by companies like Nvidia.
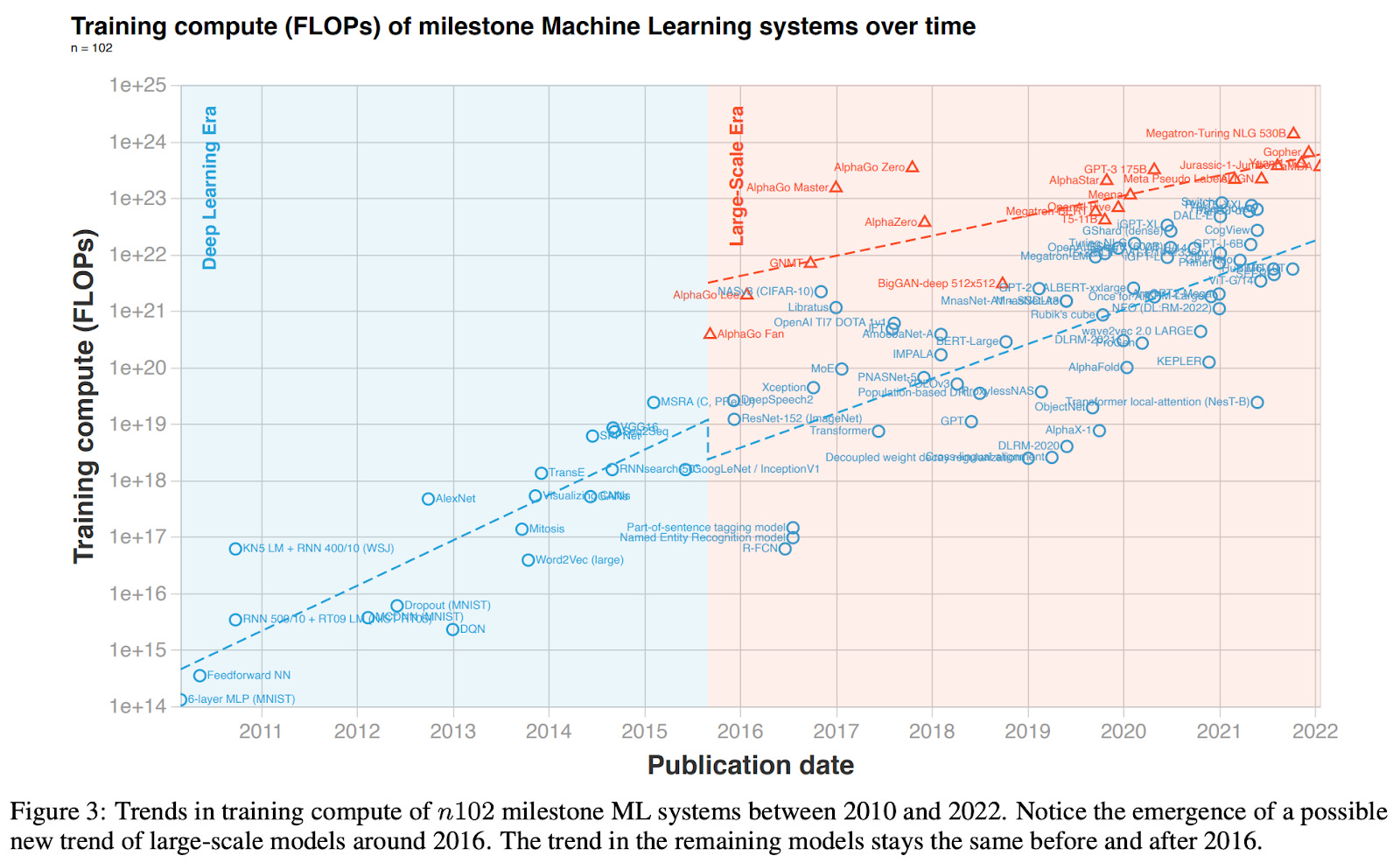
To illustrate this scaling, a recent academic paper highlighted that, on average, the compute requirement (in FLOPs) roughly increases by 0.4 OOM (order of magnitude), or 2.5x, per year. What that translates to in actual cost can be estimated as a function of the parameter size, tokens used to train, and the underlying hardware used. Semianalysis has a good chart that roughly tracks how training costs have rapidly grown over the years. If we train using the Chinchilla scaling laws, we actually need more training data (and therefore more compute) for a specific model size. As a reference, GPT-4, according to my friend Ryan at Radical, reportedly cost ~$40M (though others have reported that it costs over $100M for its final training run) but these costs likely don't include the actual architecture search/development and engineering salaries.

Source: Semianalysis
Widespread adoption of AI is still cost prohibitive given the scarcity of compute and much needed model optimizations
On the inference side (and this matters a lot!), the costs have also started becoming extreme. The top foundation models have already released their pricing (OpenAI here, Anthropic here, Cohere here), which thanks to the now slightly out of date, but still relevant work by Cognitive Revolution, we can back into various provider’s revenue in a hypothetical 20M monthly user scenario (and therefore the underlying cloud computing costs).
Using the spreadsheet in Cognitive Revolution’s blog, and the following assumptions:
10 chats/user/day
20M DAUs (daily active users). For context OpenAI has 100M+ monthly active users
Split between short/medium/long conversations: 40/40/20%
OpenAI/Anthropic/Cohere does not get preferential pricing (which is probably not true)
The top-line revenues for the top foundation model providers would be the following for their specific models:
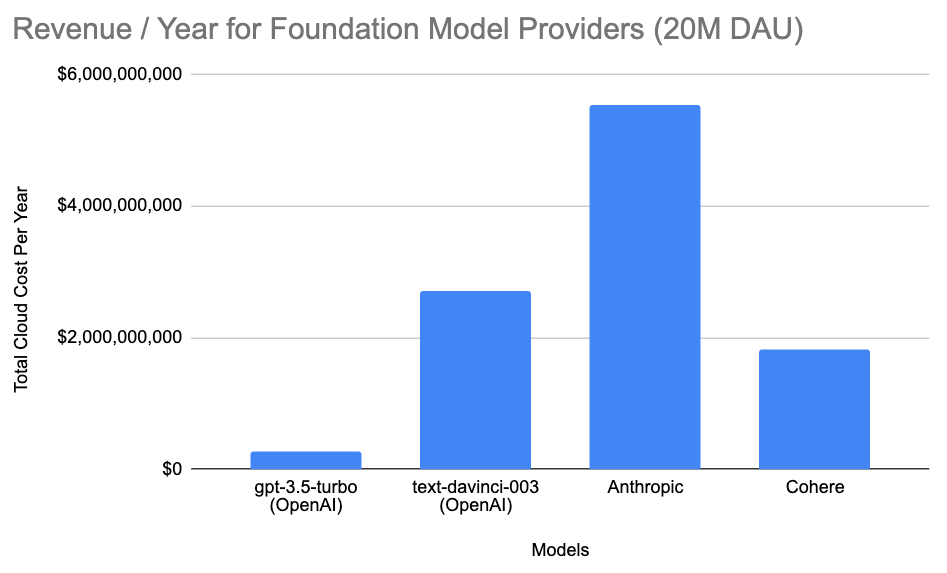
Using these headline figures, we can then back into the costs to the cloud hyperscalers. Taking OpenAI’s text-davinci-003 as an example (at 30% gross margins), it would cost OpenAI nearly $2B to run. I believe these estimates are directionally accurate (Semianalysis conducted a similar analysis for ChatGPT, which is GPT-3.5 in our example, and came up with similar figures), but please reach out if certain assumptions are incorrect!

What this shows is that not only are these companies, at scale, are revenue machines, but also that a GPT-4 scale model would cost billions to run even for 20M users (now imagine if we scaled this to 1 billion users!). If we ever hope to have widespread adoption of AI, we’ll need a) a lot more ML accelerators than we do right now, and b) there needs to be a lot of optimizations needed both at the system level and at the model serving level. We have evidence that these optimizations are happening, with MosaicML being able to train a GPT-3 quality model for ~$500k (against the nearly $5M it originally took to train) and projects like miniGPT that can run on local machines.
Regardless, we need a lot more compute as the industry labs train even larger models and startups (and everyone else) train smaller/custom models, with model serving/inference costs easily much more than 10x of training costs (AWS figures originally estimated training as 10% of total costs). But as it stands, on the ground, we’re seeing a lot of startups not able to get large amounts of reserved Nvidia A100 instances to train/serve their models. A recent Information article highlights multiple anecdotes in which the cloud hyperscalers couldn’t keep pace with sudden GPU demand, and it will be a while before the cloud vendors replenish their compute fleets with the more powerful H100 GPUs.
Given that access to semiconductors (GPUs in our case) is so critical in the advancement of AI (likely one of the core economic drivers of this decade), it would seemingly make sense for the supply chain of semiconductors be onshored or friendshored so we have steady access to compute. Unfortunately, because of the consolidation dynamics I mentioned above, the world is completely reliant on one company in TSMC, on one island (if the US loses access to leading-edge semiconductors, the accelerators we have will have to tide us over for the next few years until onshore fabs come online). As a result, TSMC has become a flashpoint in the AI wars.
The (American) Empire strikes back
Since the Biden administration took office, there has been a much more concerted effort to onshore domestic semiconductor production, as well as degrading China’s existing production capabilities and indigenous R&D. My guess is that American policy makers have become increasingly alarmed at Chinese semiconductor advances (YMTC now has the world’s densest memory chips, and TSMC nemesis SMIC can now manufacture semis at 7nm, though at subpar yields).
Specifically, the administration has placed limits on the export of “AI chip designs, electronic design automation software, semiconductor manufacturing equipment, and equipment components” into China, and is “now trying to actively degrade China’s technological maturity below its current level” according to CSIS. As an example, the US has ordered Nvidia to halt the sales of H100 and A100 chips to China, which caused a material impairment to Nvidia’s data center revenues in Q3 of last year (estimated to be in the tune of $400M). This move forced Nvidia to design a separate GPU, the H800) for the Chinese market that has lower data transfer throughput (while I don’t know the exact hit on training costs this will have, the memory mountain is a good framework to think about the effect of reduced networking speeds).
Internationally, the US has leveraged its influence to nudge its allies (including the Netherlands and Japan) to enact similar restrictions on the export of key chip making technologies to China. It has even placed “restrictions on so-called US persons supporting the development, production or use of integrated circuits at some chip plants located in China”. Domestically, things like the CHIPS Act have incentivized companies to invest more heavily into domestic R&D and production. TSMC recently pledged $40B to stand up cutting edge fabrication facilities in the US, which by the time it reaches full-scale production, should be enough to meet all US domestic demand.
China is not taking these haymakers lying down, and is readying its own massive $143B package to incentivize domestic chip production & reach self-sufficiency. As mentioned in the MAD 2023 talk that my Partner Matt and I gave, companies like Moore Threads have raised massive rounds of financing to be China’s next national champions. On the AI research front, China is similarly making heavy investments. Huawei’s recent trillion-parameter AI model, PANGU-Σ, demonstrates that Chinese AI engineers have developed the indigenous capability to build large-scale AI training systems.
As a result, all of these moves (and countermoves) have culminated in Morris Chang, the original architect behind TSMC, lamenting that “globalization is almost dead”. While I’m not as pessimistic, I do think we’ll continue to see decoupling for leading edge technologies going forward.
So why do we even care?
I think there are several second order effects which make our current semiconductor showdown so consequential should tensions between China and the US escalate to a more kinetic domain (beyond any balloon misadventures):
Taiwan’s decision to have scale production of leading-edge silicon in Taiwan was essentially a force de frappe type-moment. Given the current American reliance on Taiwan manufactured semiconductors, the implied promise of defensive aid via the traditional American policy of strategic ambiguity becomes a very tangible one, and potentially (but unlikely) up to the nuclear level. President Biden, in September 2022, did issue a much stronger statement regarding American military involvement. I see this plan out in one of two ways, should China invade Taiwan:
China invades before the US onshores its own semiconductor manufacturing (pre-2026): likely heavier US military involvement given that a strategic resource would essentially be cut off
China invades after US semiconductor onshoring: the hope here is that we have a more negotiated cool down in tensions given that there would potentially be less of a reason for the US to put American lives at risk.
Production capacity in Taiwan and maybe even Korea will be degraded or taken offline altogether. Therefore, TSMC’s decision to move parts of their leading edge production facility to the US was a positive for business continuity and resiliency, but a negative for Taiwan’s strategic value.
Consumers may also see a significant increase in the prices of hardware, given TSMC will likely pass on higher onshore production costs onto companies like Nvidia and Apple
Research labs will then be forced to train tomorrow’s models on yesterday’s hardware, and application-level startups that rely on foundational models may see their variable costs spike, and potentially become uneconomical
There will be a premium placed on startups that can leverage smaller models/less data/less training epochs for specific use cases. ASIC companies that can use older nodes in clever ways for inference/training will also benefit
Equally important are chips that are manufactured on older nodes/trailing edge. In our ML/AI context, they are critical inputs for edge inference use cases across IoT and automotive autonomy, and in a more strategic context, as inputs to things like the US Air Force’s fast jet inventory
Large, cost-prohibitive “research” models of today become “production-worthy”, in part because we take improvements in the performance-cost curve for granted (GPU, networking, etc.). If we no longer have access to continuous improvements in fabrication, we will need to rely on more algorithmic techniques (e.g. quantization, knowledge distillation, pruning, etc.). OpenAI’s recent 10x price cut using “series of system-wide optimizations” indicates there is probably more juice to be squeezed on the software side
As hopefully is evident at this point, the importance of semiconductor production for AI/ML and maintaining America's technological dominance cannot be overstated. The proliferation of foundational models and the rising tension between superpowers only reemphasizes the criticality of the development of an leading-edge onshore semiconductor ecosystem (and the failure to do so will surely introduce a fracture in our current “Pax Americana”). Currently, the confluence of factors I mentioned throughout the post creates a negative reflexive spiral, in which current geological tensions create semiconductor supply chain uncertainty, which further exacerbates these tensions.
While China's VC ecosystem has poured its investments into semiconductor “champions” with the limited venture dollars available, US VCs have chosen to focus more on the world of bits (with hardware investments mostly stopping at the design level). Now, with the US is in a race against time to replicate Taiwan’s leading edge fabrication capabilities, large companies and startups alike are now facing larger cones of uncertainty as they come up against hard constraints to compute. However, I do think this uncertainty certainly introduces interesting opportunities for the adaptable and the daring.
Across the entire stack, from the world of bits to the world of atoms, I think there are interesting opportunities for innovative builders (with varying levels of competition). Some interesting areas/food for thought include companies that fundamentally change the cost/performance curve (what comes after Transformers?), ASICs that perform better than Google's TPUs (and Microsoft’s upcoming custom accelerator), or even entrants working at the materials layer exploring novel approaches for a potentially post-silicon world. Regardless, we are in for a very interesting ride over the next decade.
Big thanks to Will Lee for the review! As always, if you’re a founder working on anything ML/AI/infrastructure related, please don’t hesitate to get in touch! I’m around on Twitter or LinkedIn!