
Peak Data


I’m probably not the first person to write about the insane leverage that LLMs confer to engineers, but Stack Overflow’s 28% layoff really got me thinking about the future of human-generated data, especially in the context of a potential model collapse (whereby “models forget the true underlying data distribution” once they are trained on machine-generated data). I explore whether we are at “peak data” in terms of both the quality and percentage of human-generated data on the internet, how this might affect the efficacy of future AI models, and potential solutions/product opportunities that exist.
For me, in the pre-ChatGPT days, my workflow as an engineer in big tech when tackling a brand new project would be reading a lot of docs, Googling/Stack Overflow’ing when something inevitably breaks, and eventually getting something serviceable working. Now, ChatGPT is my tireless companion/engineer who consistently generates well-thought out solutions (and occasionally snarky responses).
I’ll illustrate via an example:
I’m currently using Google Firebase (and Firestore) for handling a lot of our backend business logic/data storage. Because Firestore is a document-based database, I asked it to generate an entire “data model” of our app (I’m migrating from vanilla Postgres). And it generated the full data model on the first try, even reminding me about the need for data denormalization.
It then proceed to help me generate rules for field level access.

… and even some business logic via Cloud Functions to add/update non-user editable fields via Service Agents.
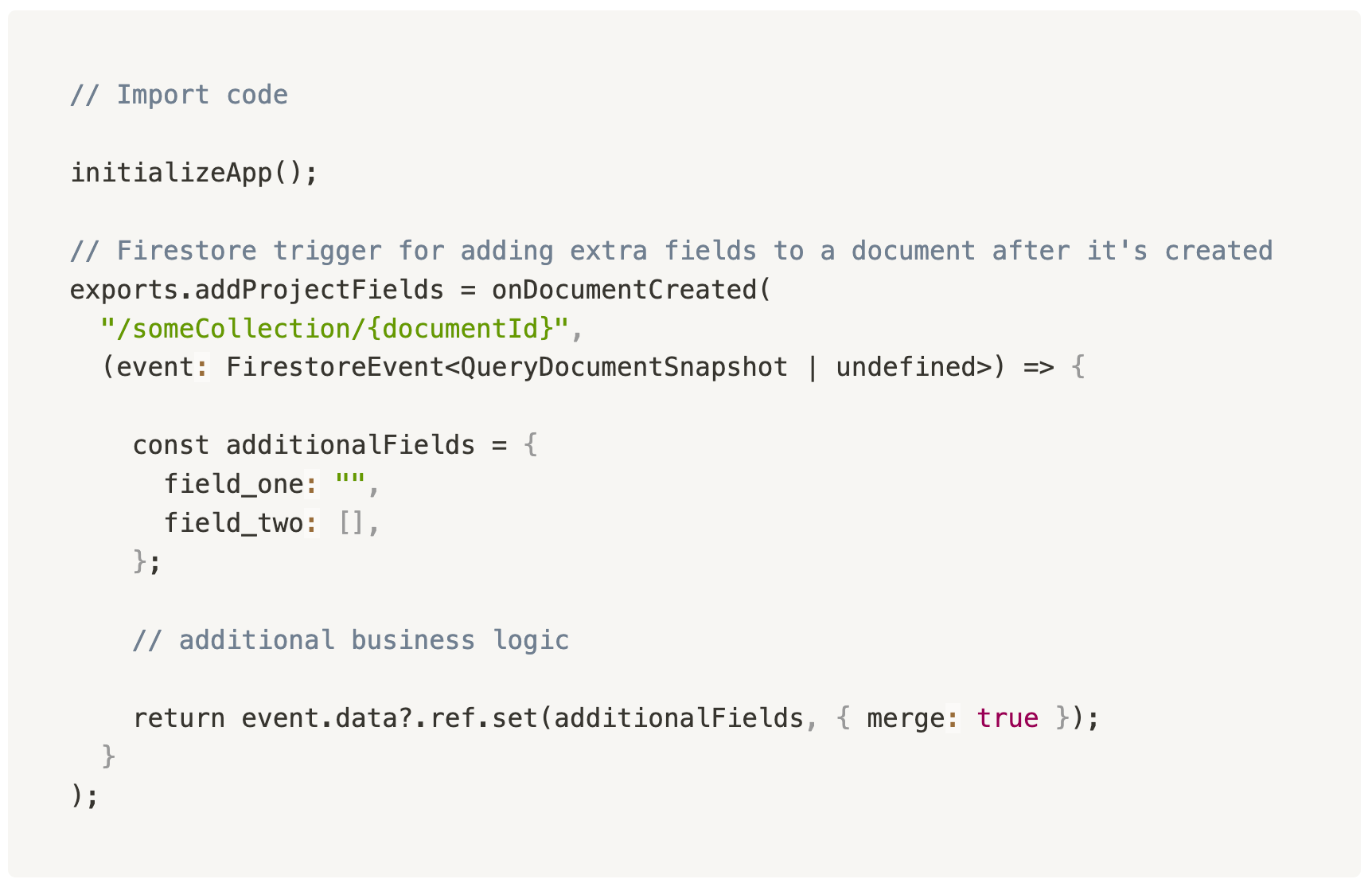
Then, once I began working on my front-end code, I ran into some ESLint issues. Instead of even writing out the fix for the error/Stack Overflowing it, I would paste the entire error message into ChatGPT to have it generate the fix — because this was faster than typing things out myself.

But, when I was using Modal (which is a new product) for some of our model inference, I had to actually read the docs! Reading? In this economy? Yes — I could do the hot RAG stuff that everyone on X/Twitter is talking about, but that requires me to set things up myself using LangChain or LlamaIndex. What I really wanted was to ask ChatGPT how to solve my specific problems for Modal.
So… how does my developer workflow relate to model collapse?
Models are trained with data up to a certain snapshot in time (for example up to September 2021):
…So all the knowledge required to solve certain types of problems, like debugging the deployment issues of a new product like Modal that comes after that checkpoint wouldn’t be in the model’s training data
…And, because ChatGPT is so good, programmers might be less inclined to ask/answer questions on a platform like Stack Overflow, and a problem that someone in the future would have for something like Modal may not get answered (or be answered in Modal’s own Q&A forums, which may or may not be sign-up gated). This would result in solutions to new problems not being in future models’ training data.
…Leading to less relevant training data for future models to solve newer problems that software engineers (or folks in other professions) might face
Additionally, more and more of the web now contains machine generated text (and other data modalities like images and video) in addition to human-generated content. This content, if used to train newer models, seems to decrease the efficacy of ML models based on academic literature that has started to appear
Even outside of machine generated content, there is the concept of data poisoning, where some actors might actively try to inject bad data into models (whether to protect IP or something else), as this article demonstrates
This results in a triple whammy where future models might have less relevant training data, less human generated data, and potentially even intentionally poisoned data! These all serve to reduce the effectiveness of future AI models
While I don’t think models are going to stop getting better any time soon, I do wonder if we have reached “peak” data quality at this checkpoint in history, where a growing percentage of content on the internet would be machine generated, and only well-capitalized companies like Open AI can aggressively protect their “pristine” data vaults from the pre-LLM days. As an aside, these technical challenges at the foundation model layer are why I’m more excited about the application layer, where startups can focus on delivering real customer value vs. constantly worrying about the shifting sands of new models that seem to come out on a monthly cadence. I don’t quite buy the “LLM wrapper” argument either (it is arguable that a highly successful company like Salesforce, at its infancy, was “merely” a UI wrapper over Oracle databases, but is obviously now so much more).
I think ultimately (and regardless of how difficult some of these solutions may be), humanity will engineer its way out of these problems, and I see some obvious solutions already:
RAG (retrieval augmented generation, whereby an AI model is able to answer a query or perform a task more accurately by leveraging external, more up-to-date or domain specific knowledge, thereby reducing the probability of hallucinations) generated solutions that is attached to some sort of user upvoting mechanism in which potential solutions would be “validated” for new training data in future models
An extension of the above: some sort of agentic approach that uses RAG + code generation to iteratively try out potential solutions, and solutions that are deemed acceptable would become new training data
Platform vendors proactively provides curated training data to foundation model vendors as a means of differentiation — so that future models will be able to ask questions of newer products (this could lead to a flywheel effect where products that have better Q&A on ChatGPT would grow faster)
If certain platforms have sufficient existing data and the incentives structures in place to entice users to continue contributing to their platform, they can provide training data for model vendors (platforms like Stack Overflow and Reddit are planning to, or already charges foundation model platforms access to their data). The open question for these platforms, however, is whether revenues derived selling data to OpenAI/Anthropic can cover the decline revenue from traditional monetization channels.
Regardless of how things shake out, I think we are entering into an era where the level of “humanity” on the internet will steadily decrease, and how user-generated content platforms continue to incentivize human contributions/what techniques foundation model vendors leverage to overcome various engineering/scientific challenges to continue giving us the “wow moments” in AI will be a very interesting trend to follow, at least until AGI gets achieved internally!
Big thanks to Will Lee, Maged Ahmed, and Andrew Tan for the review!