
A Deep Dive on AI Inference Startups

In my last post, Investing in the Age of Generative AI, I presented a framework for investing in Generative AI startups. One thing I highlighted was the heightened VC interest in “picks and shovels” startups. These companies range from model fine-tuning, to observability, to AI “abstraction” (e.g. AI inference as a service). The bet here is that as startups and enterprises add AI to their product offerings, they might be unwilling or unable to build these capabilities in-house, and would prefer a buy vs. build approach.
In this post, I conduct a deep dive on AaaS (AI-as-a-Service) startups, specifically focusing on AI inference startups (see the red box below). I’ll cover the following:
Why there’s even a need for AI inference abstraction
The convergence of developer experience, performance, and price among inference abstraction platforms implies rapid commoditization
The brutal competitive dynamics and the fact that the current available TAM is actually highly constrained
What an investor needs to believe to invest in AI inference companies, focusing on the need for massive TAM expansion, product expansion, and potential M&A opportunities. I also argue that only megafunds can “play” at this layer
Startups using composable building blocks, like AI inference abstraction platforms, will benefit in the short-term but suffer in the longer term

This will likely be the first part of a multi-part series as I explore the different layers of the “stack” for generative AI companies. Let’s dive in.
Why is there a need for AI inference abstraction?
One good way to understand the need for AI inference companies is to compare what companies needed to do if they want to deploy AI models (the world before), vs. the convenience/time-to-market advantages that inference abstraction companies provide (the world now).
The world before
Companies that wanted to venture beyond the confines of foundation model APIs (e.g. OpenAI, Anthropic) faced various challenges. On the engineering front, there are challenges with building and maintaining infrastructure (e.g. orchestration of GPU fleets, OS/CUDA/configuration management, monitoring/observability). Even once these clusters are up and running, they need to be optimized for things like maximizing utilization, elasticity, and reducing long cold start times. Erik Bernhardsson (Modal Labs) discussed some of these challenges in a recent talk for those interested.
The world now
Instead of hiring specialized talent to build/manage GPU inference clusters (which is a six-figure cost, per headcount!), companies can opt to use an AI infrastructure abstraction provider. This allows companies to use off-the-shelf models or custom-trained models, deploy these models, then access these models via an API endpoint. The inference provider then handles complexity such as scaling up/down, etc., and charges some premium over raw compute.
AI inference startups to the rescue!
Given the complexity mentioned above, a number of startups have emerged, promising to abstract away this complexity so that customers can bring AI capabilities to their products more quickly (I’ve included a subset of these companies below). I will focus primarily on startups that are more “inference-forward” vs. full stack (inference and training/fine-tuning).

There are a couple things to note here:
The developer experience has largely converged to two layers of complexity
Price and performance for top competitors in the space are similar, indicating a lack of differentiation going forward
AI inference providers are making clear developer experience trade-offs
In terms of developer experience and ergonomics, companies evaluating AI inference platforms need to choose between two layers of abstraction: platforms that offer an API-only experience and platforms that offer some level of customizable knobs.
API-only startups like Replicate, Fireworks AI, and Deepinfra have completely abstracted away all complexity so that models are accessed via an API call. This is similar to the developer experience provided by foundational model providers such as OpenAI. As a result, these platforms generally do not allow users to customize things like selecting which GPU to use for a given model. Replicate has Cog for things like deploying custom models, however.
Meanwhile, Modal and Baseten offer an “in-between” experience where developers have more “knobs” to control their infrastructure, but it’s still an easier experience than building custom infrastructure. This more granular level of control allows Modal and Baseten to support use cases beyond simple text completion and image generation.
What’s even more interesting is that the types of “knobs” that are offered are similar:
Container image configuration: Modal defines images in Python, while Baseten uses a YAML file. Developers familiar with Docker should feel right at home.
GPU resources: Modal uses Python decorators to define things like GPU resources or level of concurrency, while Baseten again uses a YAML file
Having used solutions across both layers of abstraction, I found that most competent engineers should be able to set these services up in several hours vs. the days or weeks to set up custom infrastructure. Therefore, selecting the appropriate platform is more a matter of developer “taste” and the amount of control an end user wants. In both cases, customers don’t need to hire a dedicated DevOps team.
Price & performance has converged
In addition to developer experience, the other factors that matter are performance and price. For LLM (large language model) workloads, performance largely consists of throughput (number of tokens generated per second), latency (time to first token), and stability/uptime. Here, most of the top platforms are “good enough” for common use cases, indicating a rapid commoditization in AI inference.
To illustrate this commoditization, I used Artificial Analysis (data pulled July 6 2024) to measure the inference platforms’ relative performance. I used the popular Mistral 7B model, which at the time of launch was a strong sub-10 billion parameter LLM (now outclassed by Meta’s Llama 3 8B). For brevity, I’ll only highlight token generation throughput (Artificial Analysis has a more extensive set of benchmarks). Here, we see a “clustering” of performance figures (Mistral/Baseten/Fireworks, followed by Perplexity/OctoAI, followed by everyone else). The important thing to note is that most platforms are adequate for use cases like streaming, though there’s an argument to be made for function calling use cases, where both input and output lengths can be long.

The similarity in performance stems from the fact that most of the optimization techniques are known at this point, and a good portion of the performance variance can be explained away by clear product choices (e.g. Fireworks AI being faster because it only supports a subset of custom foundation models).
Now, with most platforms having good enough performance, the next dimension that matters is price. Here, there’s also a convergence. The important thing to note here is that while pricing is similar, margins are not.

From a pricing perspective, most startups will not be able to absorb their COGS (cost of goods sold) in the long run. Companies that are better capitalized can run various experiments (e.g. amount of provisioned throughput vs. pay-as-you-go, different infrastructure set-ups) to optimize fleet-wide GPU costs more efficiently as they get more usage data. This dynamic, as we’ll see later, has a large impact on a VC’s investment strategy. For those interested, Dylan Patel from SemiAnalysis wrote an excellent article highlighting the brutal race to the bottom dynamics of AI inference.
Threat of substitutes, and limited revenue up for grabs
Given the brutal competition, what is the path to victory for AI inference companies? Here, it is helpful to take a step back and take a page out of Porter’s Five Forces, specifically looking at the threat of substitutes.

Foundation model vendors: At this point, most foundation model vendors have multiple models at different performance-to-price levels. Companies like OpenAI also offer fine-tuning services. For most use cases, buying directly from the vendors is arguably the easiest from an implementation perspective. Given the pricing parity, customers should only use an AaaS if they fear vendor lock-in, have specific performance requirements, or need to use a specific model.
Data gravity (data lakehouse platforms): the dark horse here. Databricks’ acquisition of MosaicML and Snowflake’s Arctic family of models prove that these two companies have clear ambitions to expand into AI inference. Given that both these companies already own most enterprise customers’ data (via their data lake and data warehouse products), it’s natural for them to also offer inference over this data. Therefore, while Databricks/Snowflake are not competitive with our upstarts right now, they will prevent AI inference abstraction players from expanding upmarket in the future.
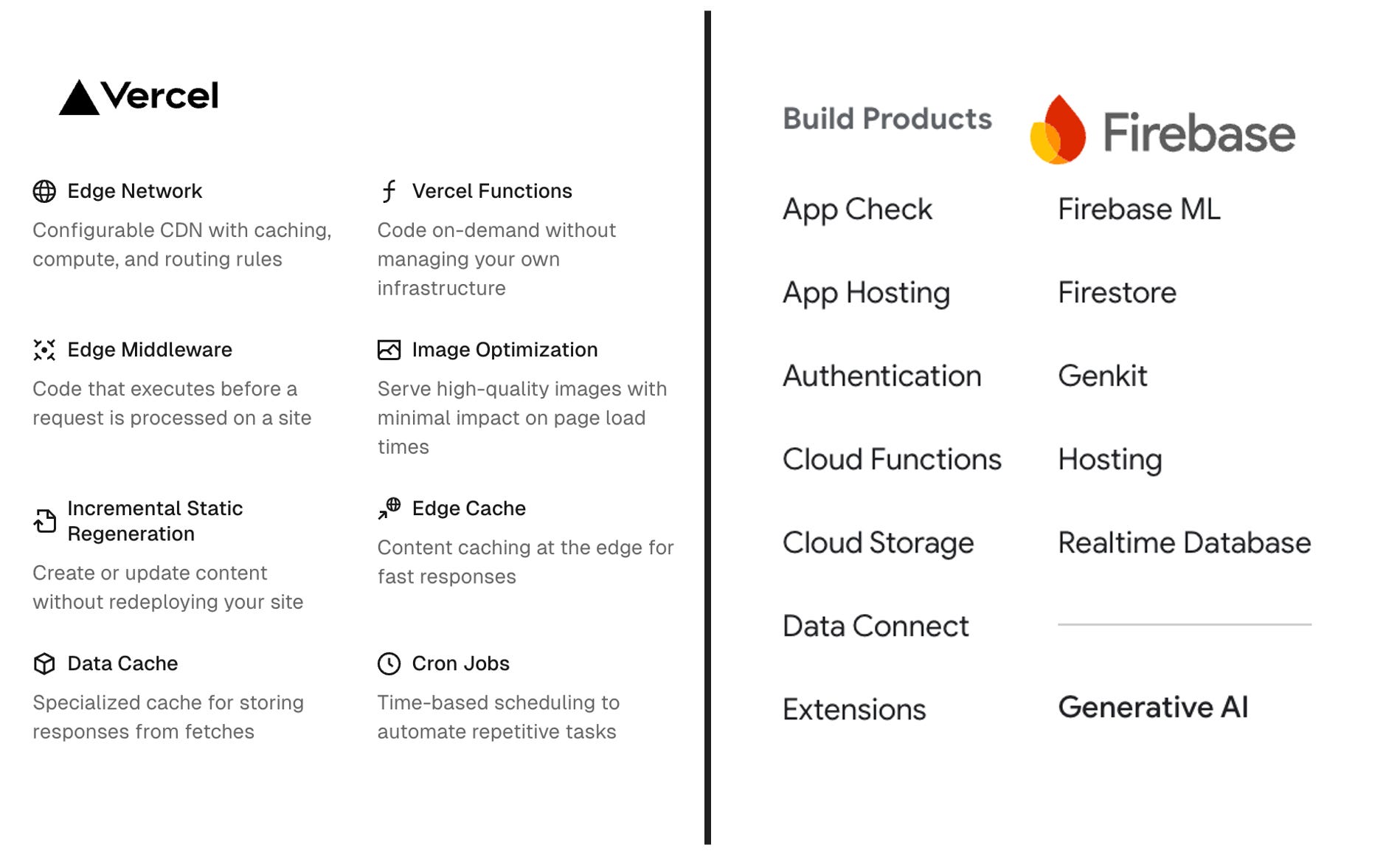
Backend abstraction: I think the real competition comes from PaaS companies like Vercel and Render (and cloud hyperscalers’ own platforms like Google Firebase). These platforms already offer the basic backend primitives that customers need to deploy a modern web app (functions as a service, databases, caches, authentication, basic monitoring & observability, etc.). Therefore, it’s logical for these services to expand their offerings to generative AI. In fact, they already do—Vercel via its AI SDK and Google Firebase via Vertex AI. I think the market dynamic here is that things become a race — do existing PaaS end up dominating AI workflows, or can our AI inference companies use abstraction as a wedge to expand to compute? What is unlikely to happen is companies using separate vendors for everything (PaaS, AI inference companies, vector database companies, etc.)
This brings us to the next question: how much revenue is really up for grabs? If we look at the PaaS market as an example, the entire category likely generates under $2B in revenue (Heroku was in the ~$500M ARR range as of 2022, and current PaaS darling Vercel is at the $100M ARR range). It stands to reason that the aggregate current-day revenues for generative AI abstraction are well under $1B (given PaaS encapsulates so many different services).
What do investors need to believe to invest in this space?
Given the current competitive dynamics in the AI inference landscape, as well as the nosebleed entry prices for these rounds, investors have to believe in three fundamental things: massive TAM expansion, product expansion, and downside protection via M&A. I’ll also leave some food for thought for funds looking to invest in this space.
TAM expansion
Even if we use the $1B figure to size the AI inference market, that only gets us to $5B in outcomes (assuming a 5x revenue multiple). This basically gets us 1 good unicorn exit! Investors have to believe there will be significant TAM expansion to justify the entry prices.
And I agree. As I wrote in my last post, the future of SaaS is that there will be a larger number of companies building solutions for smaller markets, and these SaaS products will likely need to deploy AI in their products. At an even smaller scale, there will be a long tail of profitable companies run by solopreneurs or small teams (Sam Altman even thinks AI could enable one-person unicorn). While I think one-person unicorns will be tough to achieve, there is a trend of developers leaving their big-tech or startup jobs to build profitable small software businesses.
Now, these developers will likely want to simplify their development stack as much as possible — and if our current inference platforms can own the entire compute experience, then the vendor choice becomes quite easy. While these smaller customers will have higher churn, it’s clear to me that there’s enough revenue up for grabs for VCs to make the bet.
Product Expansion
The current generative AI landscape is extremely fragmented, meaning teams that want to implement AI features would need to use a number of different vendors, from development/testing platforms like LangSmith to RAG platforms like LlamaIndex to vector databases to AI inference platforms. But the whole point of using an abstraction platform is simplicity! If teams are managing this many vendors, that’s not really simplicity. Therefore, what’s even more important than offering complete AI capabilities (e.g. model fine-tuning) is for AI inference platforms to expand and own the entire “traditional” backend abstraction platforms like Vercel and Google Firebase, and do it faster than these platforms roll out their own AI solutions. Outside of product defensibility, this also allows our AaaS companies to generate more revenue.
Downside protection via M&A
The last point is that there is a precedent for M&A — Heroku was acquired by Salesforce, Envolve (Firebase) was acquired by Google, and Parse was acquired by Meta. The way I see the market playing out is that there will be one massive winner here (just like Vercel is the current de facto PaaS via its Next.js wedge) and a handful of acquisitions. Outside of the cloud hyperscalers (AWS, Azure, GCP), there are also a number of other companies for which AI inference platforms are viable acquisition targets (e.g. Databricks, Snowflake, CoreWeave, DigitalOcean, Cloudflare), so there’s at least some level of downside protection. The major issue here is the current antitrust environment (e.g. Adobe abandoning its Figma acquisition), which might preclude the hyperscalers from larger acquisitions, and thereby cap the size of the exits for startups that don’t reach escape velocity.
What is the optimal fund strategy?
Based on the dynamics that I explained above, the AI inference market becomes a capital game (via equity or debt):
AI inference vendors need to become more “full-stack” and be the one-stop shop for software developers. This require significant R&D efforts
As developer ergonomics and performance converge, the keys to winning lie in distribution (heavy sales and marketing dollars)
To get product-market fit (or to get usage growth), platforms will need to subsidize usage, at least in the short term
All of these factors for winning require large amounts of capital. The danger for VCs is that they need to deploy hundreds of millions of dollars into AI inference companies to determine whether their bet is the runaway winner, compared to the tens of millions required for a “normal” SaaS company. Therefore, investing at this layer ends up becoming a game reserved only for the megafunds, because only they hold the reserves needed to maintain ownership at the growth stages.
Increasing abstraction will change the nature of software development
Regardless of who the ultimate winner is in AI abstraction, the trend lines are clear that software development going forward will operate at increasing levels of abstraction. What does this mean for software companies, specifically startups building AI features using these abstraction layers?
In the short term, it’s a boon for startups as companies using AI inference platforms will be able to bring their products to market even faster. Obviously, distribution then becomes the greater challenge, but we’re currently at the stage of AI adoption where not all software companies are taking full advantage of AI-powered sales and marketing tools like Clay, so there’s some alpha left on the distribution front (though this alpha is very time-boxed).
In the longer term, distribution and existing relationships will be more important than ever. Assuming companies can iterate on product features quickly (and copy top features from competitors), it stands to reason that a lot of software categories will be relatively commoditized. Therefore, the winners will be incumbents, who already control distribution and customers’ “data gravity”, and startups that can grow into an incumbent in this brief window of opportunity.
Huge thanks to Will Lee, John Wu, Maged Ahmed, and Andrew Tan for the feedback on this article. If you want to chat about all things ML/AI, I’m around on LinkedIn and Twitter!
Great post! I like to think there is a Hofstadter's law equivalent of TAM expansion in AI services: "it'll be a larger TAM than you expect, even if you've taken into account this law" :)
c.f. we still haven't scratched the surface of moving on-prem services to the cloud: https://x.com/umang/status/1811270475365994520
Great article, Kevin. While overall thesis makes sense, 1) how about the open-source AI ecosystem disrupting the market for commercial inference services? 2) What if some inference providers develop end-user applications or industry-specific solutions? - this would change their value prop and potential TAM.