
The Future of Programming: Copilots vs. Agents (Part I)

With the the launch of Github Spark and multi-model support in late October, Microsoft has fired another salvo at AI code-generation startups, bringing the competition for developer mindshare to a new level of intensity. The winner of this war will command the wallet share of nearly 30 million software developers worldwide, and more importantly, generate hundreds of billions of dollars of aggregate revenue (assuming a percentage of developers get automated).
In Part I of this post, I explore the following:
Learnings from the last-generation of code-editor wars
How to categorize the current contenders in the AI-code generation landscape
What developing without a copilot or AI agent looks like
An in-depth look at the current state of AI coding copilots, specifically focusing on Codeium, Cursor, and GitHub Copilot
Which platform is best positioned to “win” the copilot wars?
Part I will focus primarily on AI copilots, while Part II will be a deep dive on coding agents. This post is a bit more technical than my normal writings but I had a blast with this one.
Let’s dive in.
Learnings from the last generation of IDEs and code editors
Prior to the current wave of AI code generation startups, we had a “code editor” war of sorts which took place around 2015 to 2017. At the time, there were a handful of popular “newish” code editors, which included Sublime, Atom, VS Code, and a longer-tail of editors like Notepad++ and Brackets (not counting the OGs Vim and Emacs here). Over a short timespan, it felt like everyone migrated to VS Code — and it’s unclear whether it was VS Code’s inherent product superiority, the strength of Microsoft’s distribution, or its robust extension ecosystem that allowed VS Code to win (see Stack Overflow’s developer survey in 2015, 2016, 2017, and most recently, 2024 which showcased VS Code’s rapid rise).
A similar dynamic is shaping up in the world of AI coding platforms, this time with many more competitors. While AI code generation companies have collectively raised well over $1B, we’re still in the early innings of the AI coding wars, with no apparent “winner” yet. What the last generation of editors have taught us, however, is that there will only be a few contenders that will win meaningful market share, given the winner-takes-most dynamic for developer tools. And this might be the incumbent Microsoft! This means that billions of dollars will be incinerated in the meantime as heavily capitalized startups attempt to win the market. The main difference this time is the size of the prize — the winner would be automating some fraction of engineers (which is a massive TAM)!
Mapping the AI-code generation landscape
My mental model for AI-code generation startups is to break the competitors into three categories — copilots, agents, and code-generation foundation model platforms.
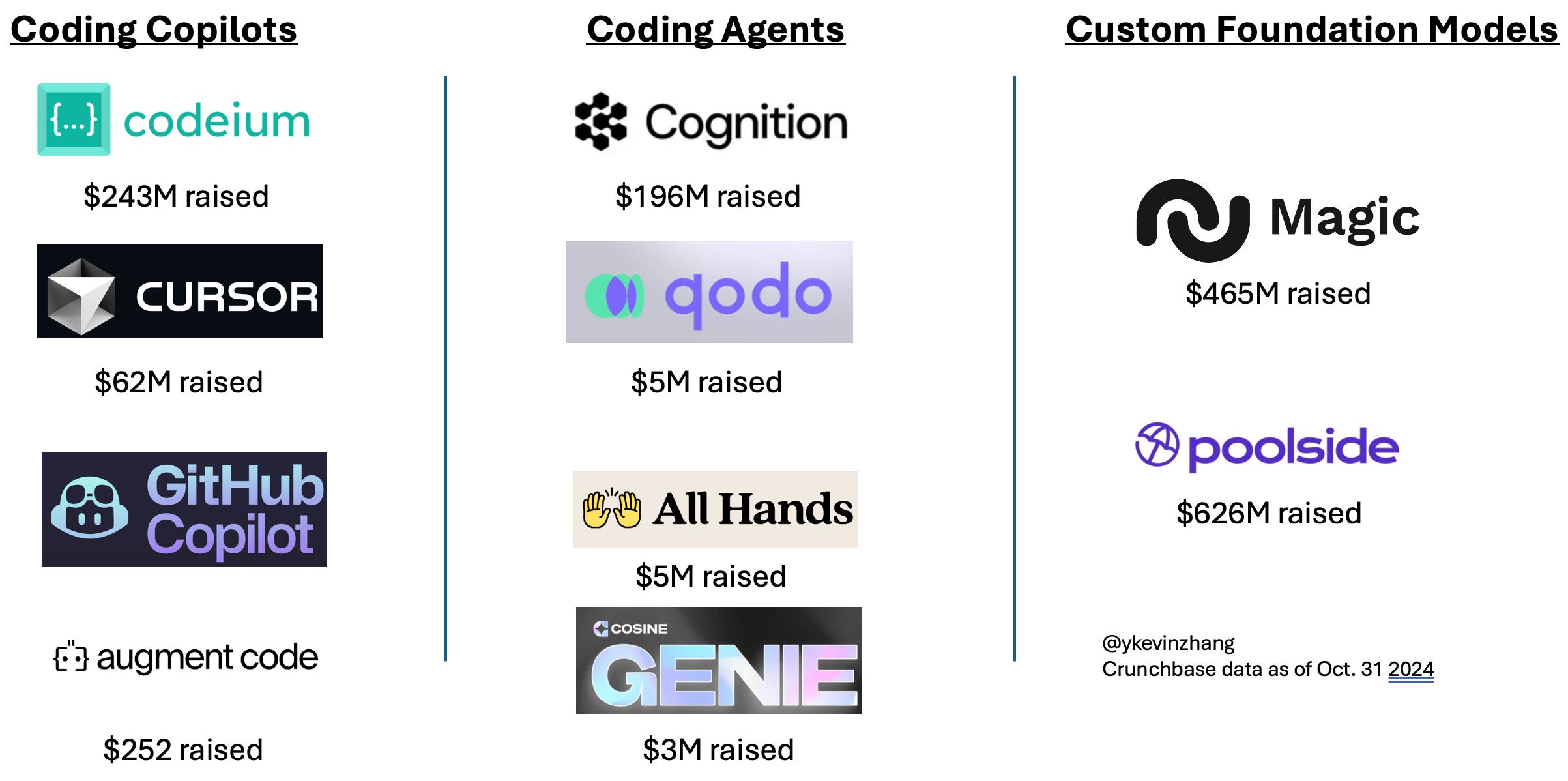
Copilots: an editor-first approach where the coding experience is more akin to what engineers are currently used to, and code generation is more of an auto-complete flow along with a chat interface
Coding agents: this is the more automated approach where based on a prompt, the coding agent would write the code, perhaps test that code, and then execute that code in some sandboxed environment
Custom Foundation Models: companies that have elected to train their custom foundation models instead of using fine-tuned version from vendors like OpenAI or Anthropic
Now, this categorization is not perfect — AI agents also allow developers to step into the code and modify it manually, and I expect copilots to add more agentic capabilities. Yet another way to think about the differences between the different platforms is whether a platform is local vs. remote (Replit would be remote-first). Over time, I expect the categories to converge as developer preferences settle into an equilibrium. The main difference now is the initial scope of ambition (e.g. custom models require the most capital and model differentiation).
How development looked like before
Before jumping into our AI copilots, it might be helpful to illustrate how development looked like using the first generation of generative AI — ChatGPT (which for me conferred a massive productivity boost).
When I was working on my last startup, I used ChatGPT in the following fashion (after I’ve scoped out the basic product requirements, business logic, and architectural design):
Read the docs of frameworks & technologies that I used (NextJS, GCP/AWS, etc.) to get a baseline understanding
Write a detailed prompt and ask ChatGPT to generate the basic design & initial code
Copy this code to VS Code, and iteratively build the rest of the app by copying snippets of existing code for ChatGPT to modify
ChatGPT was especially helpful for areas of software development that I wasn’t as familiar with (for me it would be styling with Tailwind or suggesting popular component libraries)
As large of a productivity lift ChatGPT is, it has a number of shortcomings:
ChatGPT doesn’t have context to an entire software project, which means developers need to paste code from multiples files into ChatGPT and go back and forth between their development environments and ChatGPT
LLMs (large language models) that power ChatGPT and Anthropic Claude have training date cut-offs, meaning the data used to train LLMs are only up-to-date up to a certain time. Therefore, ChatGPT might generate out of date code relative to the latest API version for something like React (I expect this to be less of a problem as things like OpenAI Search becomes more robust & widely adopted)
ChatGPT and Claude can’t “close the loop” on software development — meaning writing the code, testing it in something that resembles a realistic dev/staging environment, and deploying said software (ChatGPT now has Canvas, and Anthropic has Artifacts)
Despite strength of the latest frontier models, hallucination is still a major problem, and it takes a strong engineer to spot insidious & non-obvious bugs
Helping with blind spots / unknown unknowns. For example, for an engineer working on something net new, LLMs don’t do a great job of inferring what knowledge or context that engineer might be missing. A couple of examples here would be helping that engineer work through idiosyncrasies in AWS billing, or setting up Grafana / Prometheus (for monitoring), even when an engineer didn’t explicitly prompt it
Coding copilots and agents promise to fix some of these problems via a tighter integration of AI within a development environment, having more context of a specific project, and in some cases, offering radically different user experiences.
An in-depth look at AI coding copilots
So do AI copilots offer radically better / faster workflows for engineers? I put a handful of popular copilots through their paces, and test out Codeium, Cursor, and Github Copilot.
Here’s how I set up the experiment:
I generate a simple chatroom, using Google’s Firebase / Firestore as a backend, and NextJS on the frontend. This is a good representation of an app of some complexity
For each project, I set up a separate repository and build the application from scratch
I’ll be deploying each project / setting up GCP manually (to save time, I will only set up the backend once), and will be paying special attention whether these platforms help set up configurations correctly (e.g. tsconfig.json and firebase.json).
At this point, most platforms (and even things like ChatGPT and Anthropic Claude are quite good at function-level generation). The key here is how well these platforms give engineers leverage at the system-level
I’ve built chat-based apps several times now, both at my time at Quip and at my last startup, so I directionally know what “right” looks like
Codeium
Codeium’s AI Copilot is delivered as an extension on popular code editors and IDEs (e.g. JetBrains and Xcode). I used Codeium on VS Code. After installing the extension, I began to generate the foundations of my app using Codeium’s built-in chat feature (see prompt below).

Codeium has a number of supported models, including an unlimited-use base model, as well as frontier models available for paying users (GPT-4o, Claude 3.5 Sonnet, etc.). I’m used Codeium’s own Premier model, which is a fine-tuned version of Meta’s strong Llama 3 405B model.
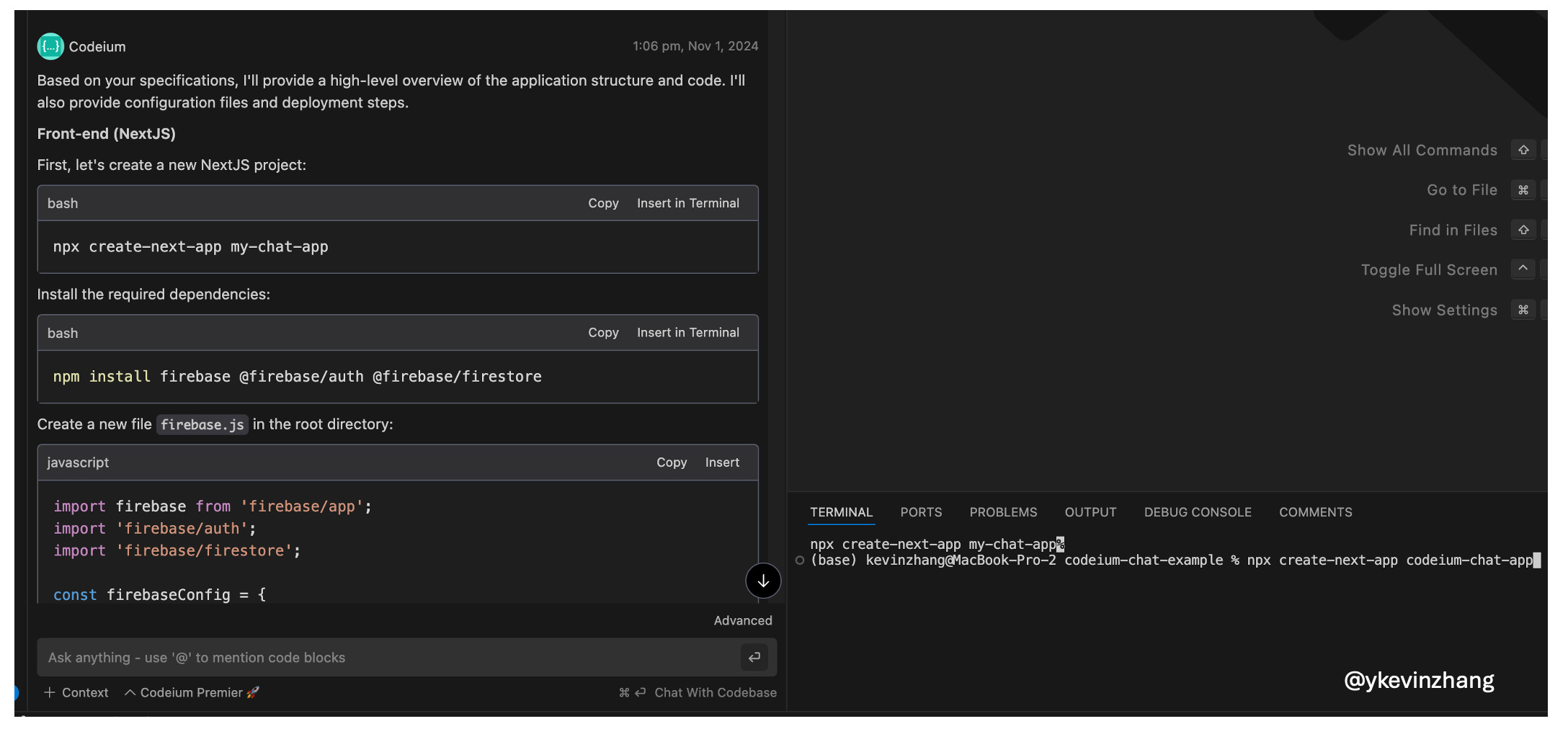
The powerful thing Codeium (and other copilots) has compared to ChatGPT is that I can directly insert the generated code into my working file, or insert commands into VS Code’s terminal.
Right off the bat, I noticed some issues:
The generated NextJS frontend uses the older “pages router”, instead of the newer “app router”. See the detailed explanation here. This forced me to make changes manually. Going forward, engineers writing code will face the problem that the bulk of the training data will be code using older API versions / language versions, so whenever an engineer needs to actually read the latest docs, coding velocity would drop to “human” levels. This is not a problem isolated to Codeium, but all large language models where more of the training data naturally uses older data (I had first called attention to this last year in my Peak Data post).
On the Firebase side of things, I was told to manually create configuration files that would have been automatically generated via Firebase’s command line tool
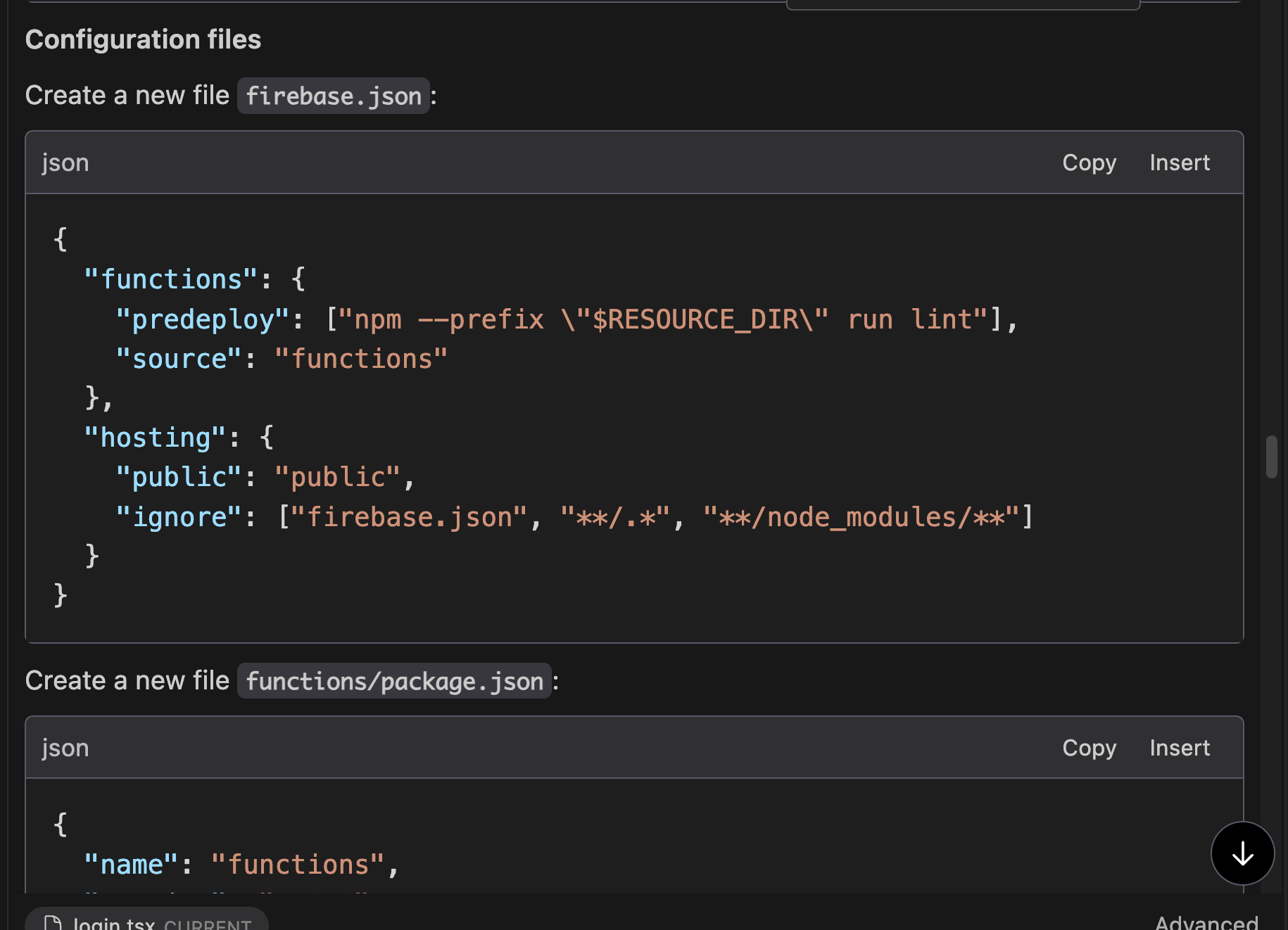
I also found myself manually upgrading from Firebase’s older, “namespaced API” convention to the “modular API” convention. This furthers my belief that the pace of version upgrades for various frameworks will greatly outpace the updates / weights of LLMs. Therefore, AI code-generation platforms will need to be extremely thoughtful in terms of when they use an LLM’s internal knowledge, and when to consult updated API documentation using RAG (retrieval augmented generation).

Once some of the more obvious issues were fixed, I tried running my code, which failed miserably, as it was missing a number of things (non-exhaustive list below):
Firestore rules to allow reads/writes (listen to incoming messages / send messages)
The inline Tailwind styling CSS generated simply didn’t work
Various program logic flaws / deficiencies that required further prompting & manual fixes
The initial steel thread was something quite limited and devoid of styling:

After another round of prompting, specifically focused on styling, did make things quite a bit better, but it’s still a far cry from the chat interface that Will and I worked on in the past (see screenshot below)

Cursor
Next up, we have Cursor, which originally started as a fork of VSCode, but has since then diverged quite a bit in terms of user interface (and is rumored to have investor interest at a ~$2.5B valuation). Here, I used the same prompt from the Codeium example. The main difference is the model selection where I used the October 2024 version of Anthropic’s Sonnet 3.5. This worked much better than Llama 3.
I quite liked that Cursor was able to generate a suggested project structure (though it did use the older pages router initially). I also liked that it helped with the “unknown unknowns”. For example, it wrote Firestore rules without being prompted, and also suggested things like adding analytics / instrumentation. These helpful “nudges” serve to encourage engineers to add things they might have otherwise missed.
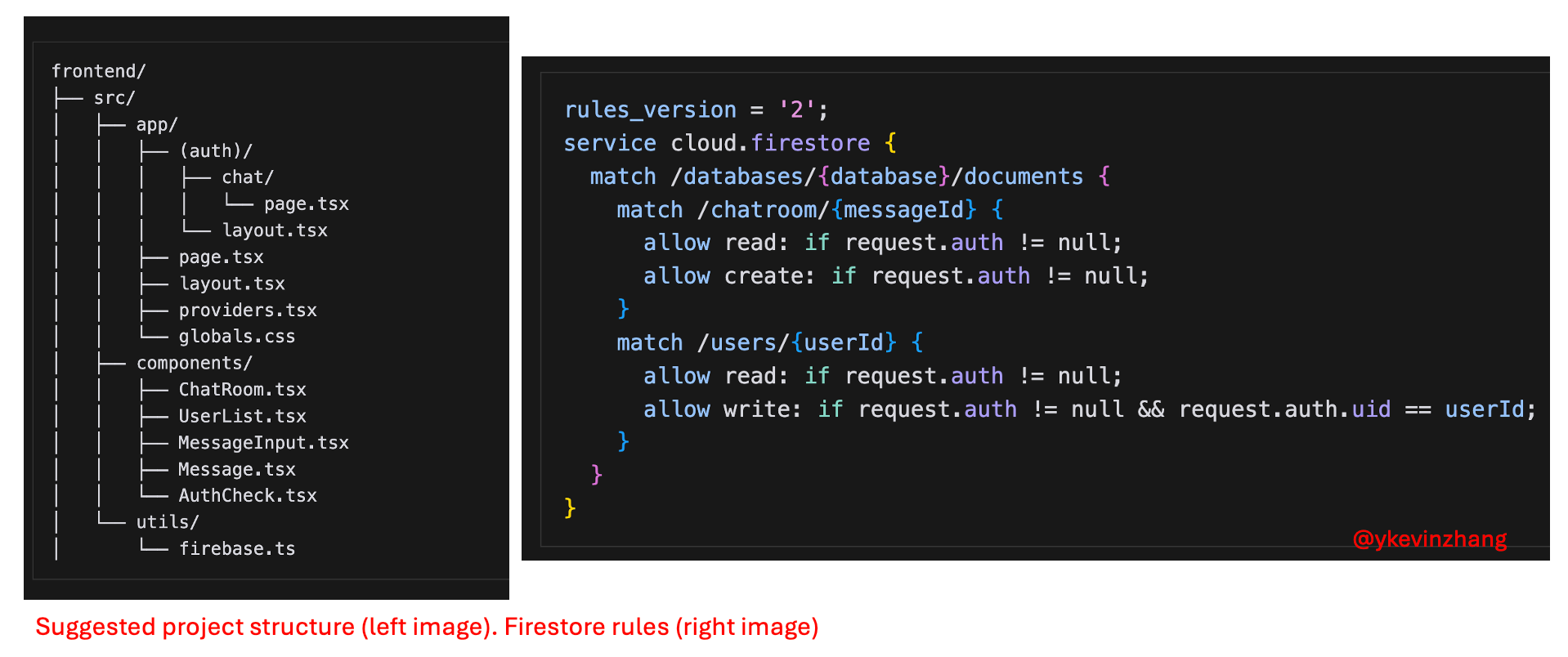
The code generated wasn’t immediately runnable, but I was able to fix major issues quickly, and the resulting front-end looks much more polished.

Cursor makes a number of fairly intuitive UX choices. As an example, a user can select a block of code, type CMD-K (on Mac), and use natural language to modify that specific block of code. Now, other copilots have this capability as well — the difference is how these features are presented to the user that makes Cursor more enjoyable to use.

Cursor isn’t devoid of issues — when I clicked “Apply” to apply the generated code from Cursor’s chat interface into my code editing surface, it created a file using the pages router structure, even though it had already generated newer code using the app router.

There were also issues with formatting in the chat window where Cursor at times wasn’t able to discern generated code and text (I’ve also seen this issue in ChatGPT).
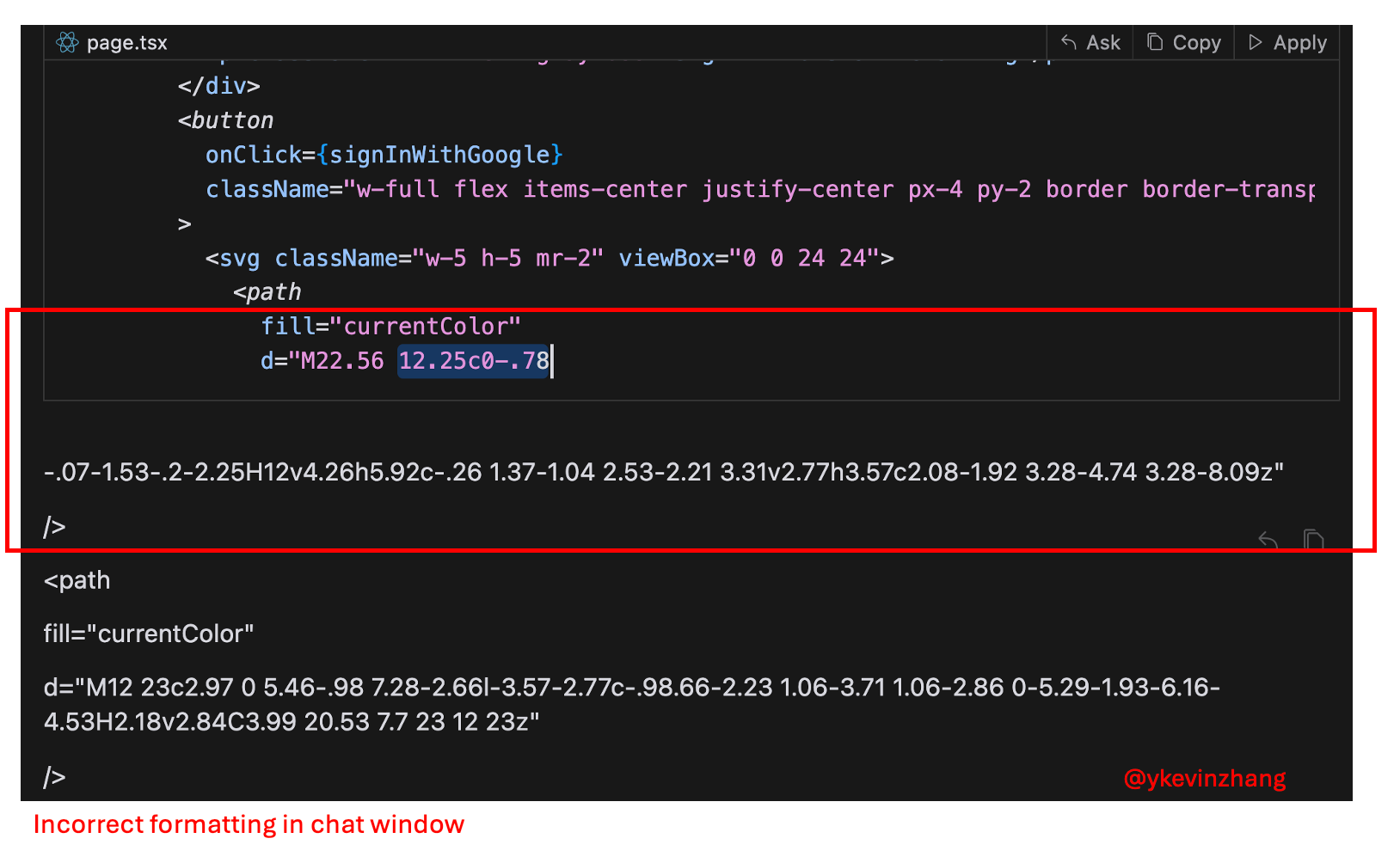
On the copilot side of things, Cursor probably came the closest to giving me that ChatGPT magical “aha” because the user interface is so thoughtfully implemented, while being familiar enough for someone coming from vanilla VS Code.
GitHub Copilot
Finally, we have the incumbent offering in GitHub Copilot. Originally launched in 2021, it’s grown into a monster business, accounting for 40% of GitHub’s revenue growth the past year, and with a run-rate that is higher than GitHub’s entire run-rate at the time of Microsoft’s acquisition. Despite Microsoft’s $10B+ investment in OpenAI, the major news from Redmond recently is that Copilot now supports multiple models (Anthropic’s Claude Sonnet 3.5 and Google’s Gemini models). Github Copilot has taken a similar approach to Codeium in that it offers extensions for a number of code editors and IDEs, including VS Code, JetBrains, and even Apple’s Xcode.
Like before, I prompted Github Copilot to generate the overall project structure and initial code, this time using OpenAI’s GPT-4o. Here, GPT-4o completely disregarded my command to add styling. Another thing I noticed is that Copilot has taken the trouble of integrating Copilot deeply into VS Code, to the point of almost hiding its AI capabilities amidst its other features.

Once I got the hang of the user interface, the actual feature set of GitHub Copilot is quite similar to its startup rivals. One current differentiator that some of Copilot’s startup rivals doesn’t seem to have yet is the ability to edit multiple files, which actually speeds up development quite a bit (see image below).
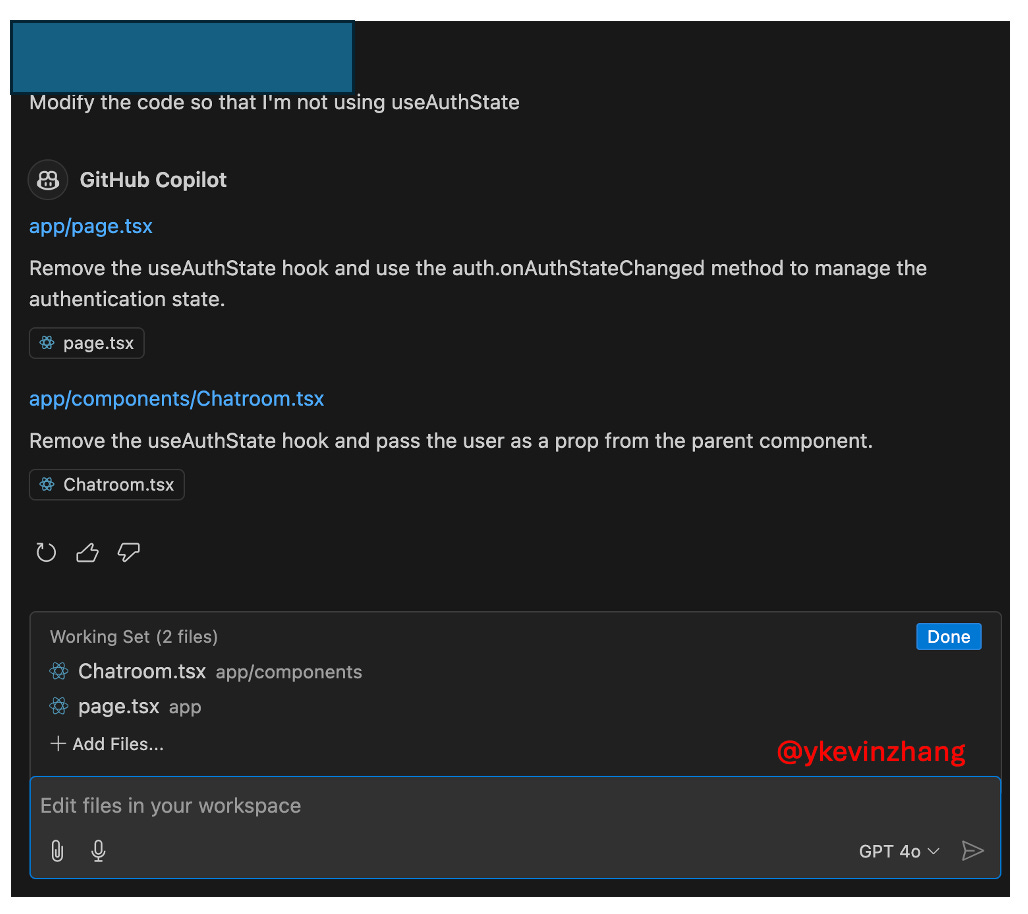
Once I did a few rounds of chats & code edits, I ended with something similar to Cursor’s efforts.

Learnings from code-generation copilots
After implementing the same code three times, my observations are as follows:
Twitter thought leadership is divorced from reality. While it’s fairly trivial to implement something simple with AI, building something production-ready does take additional thoughtfulness (setting things up on AWS, monitoring/visibility, robust testing strategies, etc.)
That said, copilots and agents are only going to get better from here, and it’s only a matter of time before these platforms automate/augment more of an engineer’s daily workflows
On the product feature side of things, there are certainly a number of differences between the three offerings, but the main “thrusts” are the same — a chat interface, code autocomplete, in-line AI editing, etc. At this point in the game, I think the main technical differences between the different offerings lie in each product’s RAG implementation and internal prompts
The choice of models also matters a lot. For me, Anthropic’s Sonnet 3.5 gives me the best “vibes”
The biggest difference comes from the user interface. And we’re clearly in the early days! Many products in the space still feel more “bolt-on” than AI-native. One example of this is that the chat interface is in the same window as the actual code editor — meaning that code can get cut off on smaller screens (see image below). Over time, I expect companies to figure out the optimal way to embed AI in a traditional code editor / IDE. I also think a lot of knobs will be abstracted away (users shouldn’t need to choose between Llama 3, Claude, and OpenAI, they just want the best tool to get the job done)
As it stands, different vendors have chosen different angles of attack in terms of product design / user interface, with Codeium / GitHub Copilot delivering their offerings via extension, and Cursor building a net new product from a VS Code fork, giving them more freedom to make bolder product decisions

So who will win the code generation copilot war?
The game is Microsoft/Github’s to lose, given its distribution and massive engineering resources. Github also has the additional advantage of its existing relationship with enterprises. For many companies, code is their core IP, and these companies will not easily entrust this IP to an early-stage startup (and why ChatGPT is blocked at many companies). Despite these advantages, at least on the product side of things, Github Copilot somehow feels the most “janky” to use compared to Cursor/Codeium. And this is an opportunity for a scrappy startup to kill the Goliath that is GitHub Copilot!
Right now, the market is in a “land grab” phase, with startups desperately trying to win developer mindshare. The three ways that companies are winning / differentiating, at least in the short-term, are:
UX: despite these three copilots having similar feature sets, there are subtle UX differences (how commands are triggered, placement of functionality, etc.). This actually makes a huge difference in developer ergonomics! Here, I think “owning” the UX end-to-end vs. having an extension-based approach is superior (greater control over UX/UI, not having to compete with the editors own AI solutions)
Medium-level technical differentiation: while startups analyzed aren’t training their own models, there is a degree of technical differentiation that stems from things like RAG implementations, model fine-tuning, and hand-tuned internal prompts. I don’t expect these moats to last too long, however
Distribution: this is where Github Copilot has the clear edge, and startups need to do something to achieve the sort of virality that VS Code had during the 2015-2017 timeframe.
The more fundamental / longer-term question is which paradigm of software development will win out — is it coding copilots or agents? Do companies all eventually need to train their own models? Is the future of development browser-based, or would engineering look more similar to our current approach?
And that concludes Part 1 of this post! Part II of the post will focus on AI agents, and how they stack up against our coding copilot (which will hopefully answer some of the questions I raised). Till next time!
Huge thanks to Will Lee, Maged Ahmed, Wai Wu, David Qian, AJ Chan, Khash Zadeh, Lisa Zhou, Kunal Desai, and Andrew Tan for the feedback on this article. If you want to chat about all things ML/AI, I’m around on LinkedIn and Twitter!
Thanks for sharing. I have played around with a bunch of these tools over the last 9 months and got similar results. Thanks for sharing!
Great post!